
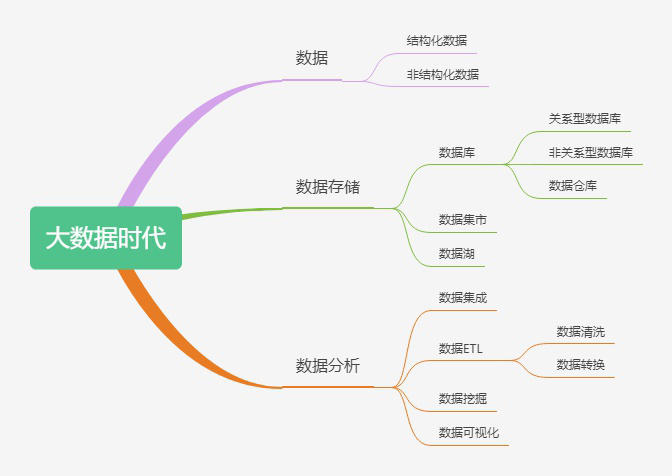
大数据时代必须了解的18个概念(数据仓库、商业智能、数据可视化……)
01.什么是大数据?
数据是对客观事实进行记录的一种符号,可以是数字、文字,也可以是图片、音频、视频。大数据是指无法在一定时间范围内用常规软件进行捕捉、管理和数据的数据集合。
大数据具有"5V"特点,即数据量大、数据多样性、价值密度低、增长速度快、数据质量低。
大数据时代强调数据的全部,而不是局部的样本数据。由于大数据的价值密度低,我们要接受这种模糊和不精确性。通过对数据的研究,发现以前不曾发现的联系,而不是像小数据时代,先通过假设,然后再用数据来验证。也就是说,在大数据时代,对相关性的重视程度要强于因果性。
02.什么是结构化和非结构化数据?
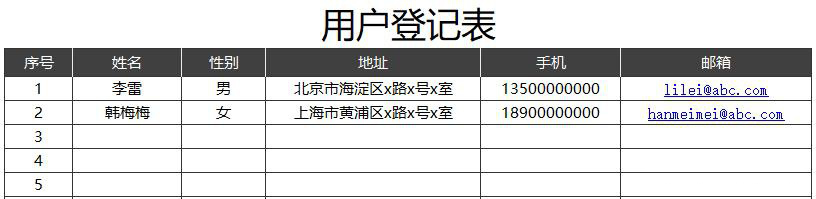
结构化数据是适合用二维表格展现的数据。每一行是一条记录,每一列是不同的字段。
以电商网站为例,用户信息就可以用结构化数据来存储。每位用户就是一条记录,而每位用户又有姓名、性别、地址、手机、邮箱等字段,这样就形成了一个二维表格。
非结构化数据不适合用二维表格来展现,比如文档、图片、音频、视频等。非结构化数据的格式多样,难以标准化和理解,因此在存储、检索、利用上都需要更加有效的方法和技术。
03.什么是数据库?
数据库从字面意思来看就是存储数据的地方,但数据的存储不是杂乱无章的,而是按照一定的规则来存储的,具有可共享和便于管理的特点。数据库被视为电子化的文件柜。用户可以对数据库中的数据进行增、删、改、查等操作。
数据库可分为关系型数据库、非关系型数据库、数据仓库等类型。
04.什么是关系型数据库?
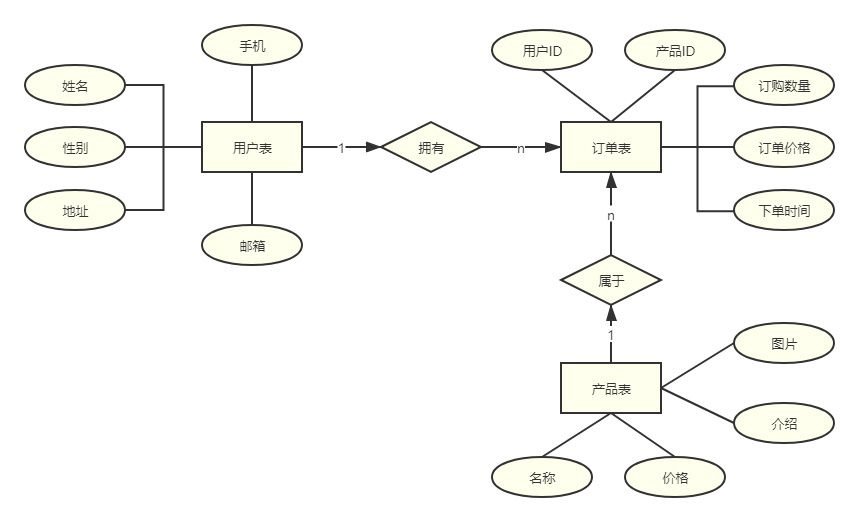
关系型数据库是指使用关系模型来组织数据的数据库。关系模型可以简单理解为二维表格模型,以行和列的形式存储数据,因此适合存储结构化数据。关系型数据库就是由多个二维表格及其之间的关系组成的数据库。
常见的关系型数据库有MySQL、SQL Server、PostgreSQL、Oracle等。
以电商网站为例,除了用户信息之外,还要记录产品信息和订单信息。为简化起见,每个订单只包含一种产品。产品包括名称、价格、图片、介绍等字段,订单包括所属用户、相关产品、订购数量、订单价格、下单时间等字段。一个用户拥有一个或多个订单,而一个产品也会属于一个或多个订单,这样就建立了用户、订单和产品之间的关系。
05.什么是非关系型数据库?
相对关系型数据库而言,非关系型数据库抛弃了固定的二维表格结构,存储机制灵活,比如键值对、文档、图形等格式都可以进行存储。
常见的非关系型数据库有Redis、MongoDB、Cassandra等。
性能是非关系型数据库最大的优势。由于关系型数据库中的关系模型会占用掉90%的硬件资源及计算时间,对于有大量不需要关系功能的数据处理,非关系型数据库的性能是非常高的。
另一方面,正是由于缺少数据表之间的关系,非关系型数据库很难在多个表之间做非常复杂的数据查询。
06.什么是时序数据库?
时序数据库是一类特殊的非关系型数据库,全称是时间序列数据库。经研究发现,机器设备、传感器、系统日志等产生的数据有如下明显的特征:
数据是时序的,即按照一定时间顺序生成;
数据极少有更新或删除操作;
数据产生频率快、数据信息量大;
数据往往带有位置信息。
传统的关系型数据库或非关系型数据库对于这类数据,在性能提升上极为有限,只能依靠集群技术,投入更多的计算资源和存储资源来处理,造成企业运营成本急剧上升。而时序数据库可以有效地处理庞大的数据,通过创新的列式存储和先进的压缩算法,使用的计算资源不到传统方案的1/5,存储空间不到通用数据库的1/10。
常见的时序数据库有InfluxDB等。
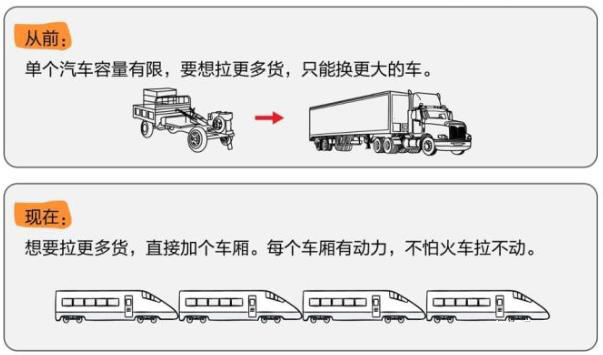
07.什么是分布式存储?
分布式存储是相对于集中式存储而言的。分布式存储是由标准服务器(硬件)和分布式文件系统(软件)组成的,可扩展至千台硬件节点,支持块存储、对象存储、文件存储等多种类型统一管理。
常见的分布式文件系统有HDFS、Ceph、GFS、GPFS、Swift等。
举个通俗易懂的例子,如果把存储比喻成车厢,数据比喻成货物。集中式存储方案下,如果要想拉更多的货物,只能更换更大的车厢。而分布式存储方案,直接增加车厢就可以了。有了分布式存储技术,存储EB级别(1EB=1024PB=1024*1024TB=1024*1024*1024GB)的海量数据库都不成问题。
08.什么是数据集成?
由于开发部门或开发时间的不同,企业中往往有多个异构的、运行在不同的软硬件平台上的数据库,这些数据库彼此独立、相互封闭,使得数据难以在系统之间交流和共享,从而形成了"信息孤岛"。随着信息化应用的不断深入,企业内部之间、企业与外部的信息交互的需求日益强烈,急切需要对已有的数据进行整合,打通"信息孤岛",这就是数据集成的意义。
数据集成是把不同来源、不同种类、不同格式的数据在物理上或逻辑上进行集中,为企业提供全面的数据共享。数据集成主要解决的问题是各个数据源的异构性,包括数据库的异构性、通信协议的异构性、数据类型的异构性、数据取值的异构性等。
09.什么是数据清洗?
数据清洗是一种清除错误数据、去掉重复数据的技术。数据经过清洗之后,可以还保存到原来的数据库中,也可以和数据集成联系在一起,最终保存到集成后的数据库里。
举几个数据清洗的实例:
1.在用户信息表中,规定有姓名、性别、地址、手机、邮箱五个字段是必填的。而某些用户缺少某些字段的值,因此需要补充这些数据。
2.英文的姓名之间规定要有空格,而某些姓名没有空格,比如"JohnSmith",就需要修正这类错误。
3.有些数据表的金额单位是元,有些数据表的金额单位是万元,数据集成时就需要统一单位。
4.两条用户记录完全重复,需要进行去重处理。
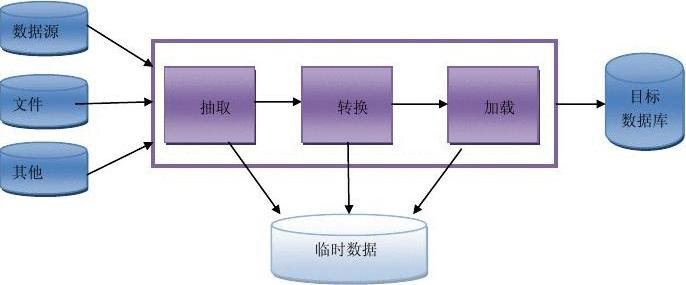
10.什么是ETL?
ETL是Extraction、Transformation、Loading三个单词的首字母缩写,指的是数据抽取、转换、加载的过程。
数据抽取是从不同的数据源中获取我们需要的数据的过程,和数据集成的概念类似,这个过程往往会做一些数据清洗和数据转换。数据转换的任务主要是进行数据格式的转换和一些业务规则的计算。数据加载通常是指在数据清洗和数据转换完成后,写入到目标数据库中去。
11.什么是数据分析?
数据分析是基于商业需要,有目的的对数据进行收集、整理、加工、分析,最终提炼有价值的信息的过程。
数据分析的四个步骤:
需求分析、明确目标;
数据收集、加工处理;
数据挖掘、数据展现;
分析报告、提炼价值。

12.什么是数据埋点?
所谓数据埋点就是从应用的特定流程中收集一些信息,跟踪用户使用的状况,用来提供运营的数据支撑,进一步优化产品。
常见的信息包括独立访客数(UV)、页面浏览量(PV)、页面停留时长、页面跳出率、交互元素的点击事件等。
数据埋点通常有两种方式:
第一种是研发团队在产品中注入代码,并搭建响应的查询平台;
第二种是借助第三方数据埋点工具,如神策数据、百度统计等。
13.什么是数据仓库?
数据仓库 (Data Warehouse) 简称DW,存储大量数据的集成中心。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision-Support)。它为企业提供一定的BI(商业智能)能力,指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
14.什么是数据集市?
数据仓库是面向整个企业的,而数据集市是面向部门的,因此规模更小,由业务部门设计、开发、管理、维护,可以理解为是数据库的子集。
数据集市就像宜家楼上的家居展厅,正如其名字"集市"一样,是一个面向最终顾客的数据市场。在这里,数据(家具)以一种更加容易被顾客接受的方式组合在一起。顾客的需求是分场景的,比如客厅、书房、卧室、厨房等,因此我们需要创建多个数据集市(展厅)。

15.什么是数据湖?
数据湖至今仍然没有一个特别标准的概念,比较统一的是数据湖存储的是未经加工的原始数据,包含结构化和非结构化的各类数据。数据湖就是一个存储了企业所有原始数据的存储,对于这些原始数据的管理则更加复杂。
以宜家家居为例,数据湖的原始数据就相当于拆散的零部件,顾客可以根据实际需要挑选零部件后自行组装。
16.什么是数据挖掘?
数据挖掘就是从大量的实际应用数据中,提取隐藏在其中的有价值的信息的过程。
一般而言,数据挖掘分为两类:一类是监督学习,另一类是无监督学习。监督学习是对目标需求的概念进行学习,通过建立模型来实现从观察变量到目标需求的有效解释。无监督学习没有明确的标识变量来表达目标需求,主要任务是探索数据之间的内在联系和结构。
数据挖掘融合了多学科领域的知识,常用的算法有分类、聚类分析、关联分析、趋势与演化分析、特征分析、异常分析等。
17.什么是数据可视化?
数据可视化就是借助图形化的手段,清晰有效地传达与沟通信息。
利用人类对形状、颜色的敏感,有效地传递信息,帮助用户从数据中发现关系、规律和趋势。常用的数据可视化图表有柱状图、条形图、饼图、雷达图、折线图、堆积图、散点图等。
18.什么是商业智能?
商业智能(BI,Business Intelligence)是对商业信息的搜集、管理和分析过程,目的是使企业决策者获得洞察力,做出对企业更有利的决策。
从技术层面上讲,商业智能不是什么新技术,它只是数据仓库、联机分析处理、数据挖掘、数据备份和恢复等技术的综合应用。

19.结语
远齐科技基于成熟的软件架构、互联网、物联网、大数据、人工智能等技术构建面向未来的集成开发平台系统。在自有集成开发平台基础上,基于最佳业务实践开发出丰富的软件功能模块、业务系统,为企业提供高效的定制化开发服务。




 地址:北京市朝阳区朝阳路71号锐城国际1609室
地址:北京市朝阳区朝阳路71号锐城国际1609室 邮编:100123
邮编:100123 手机:15210221375
手机:15210221375 邮件:
邮件: 微信公众号:远齐科技
微信公众号:远齐科技 微博:
微博: 网站:
网站:
 京公网安备 11010502040327号
京公网安备 11010502040327号